|
I am a fifth year Ph.D student in the Department of Automation at Tsinghua University, advised by Prof. Jiwen Lu. In 2020, I obtained my B.Eng. in the Department of Electronic Engineering, Tsinghua University. I am broadly interested in computer vision and deep learning. My current research focuses on 3D vision and Video analysis. |

|
|
|
|
* indicates equal contribution |
|
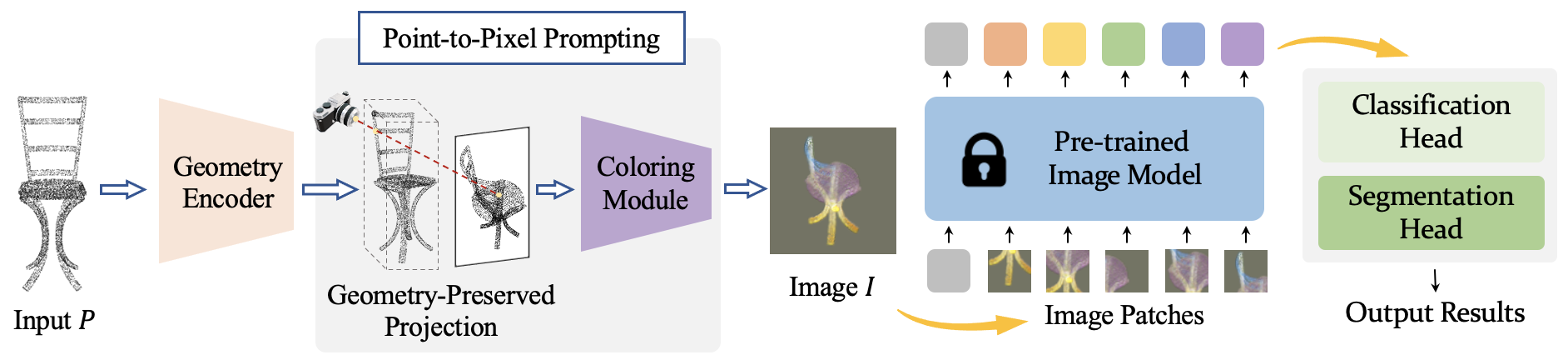
Ziyi Wang*, Xumin Yu*, Yongming Rao*, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 Spotlight [arXiv] [Code] [Project Page] [中文解读] P2P is a framework to leverage large-scale pre-trained image models for 3D point cloud analysis. |
|
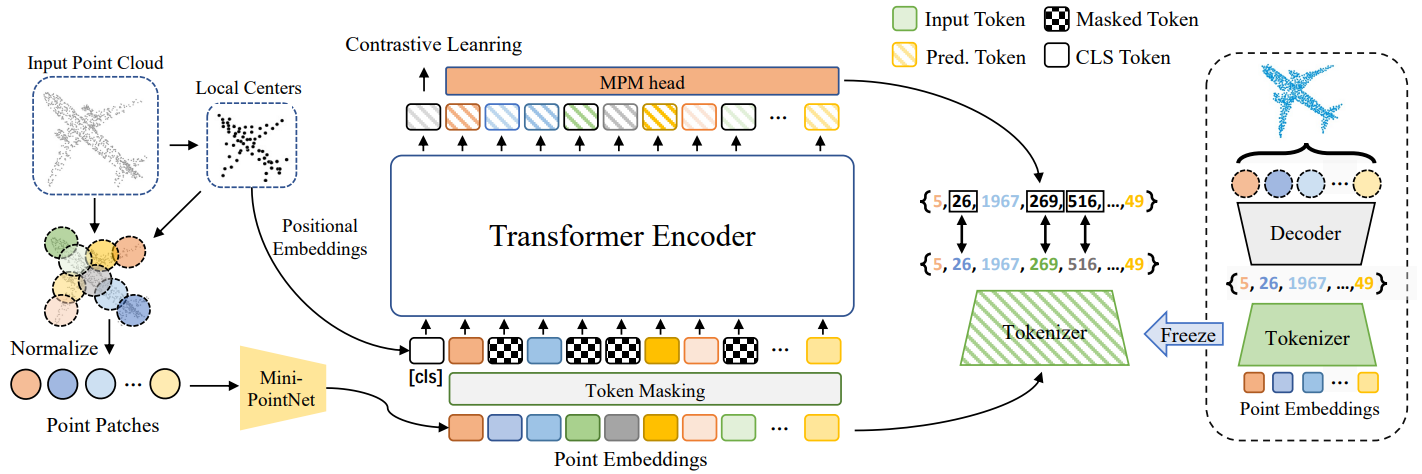
Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] Point-BERT is a new paradigm for learning Transformers in an unsupervised manner by generalizing the concept of BERT onto 3D point cloud data. |

|
Xumin Yu*, Yongming Rao *, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [supp] [Code] [中文解读 (by CVer)] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
|
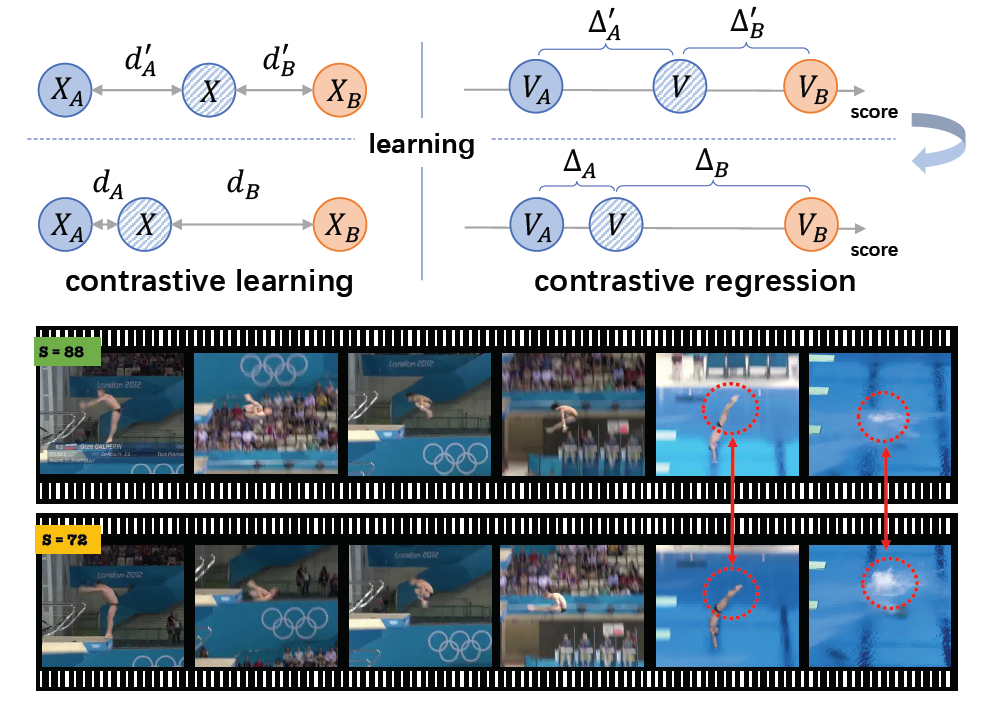
Xumin Yu*, Yongming Rao*, Wenliang Zhao, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We propose a new contrastive regression (CoRe) framework to learn the relative scores by pair-wise comparison, which highlights the differences between videos and guides the models to learn the key hints for assessment. |
|
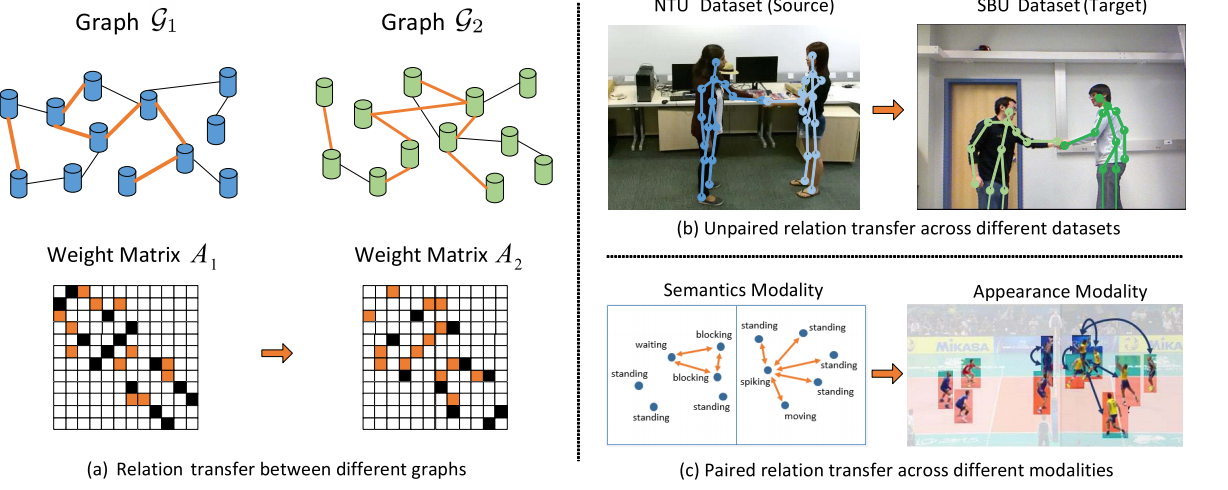
Yansong Tang, Yi Wei , Xumin Yu, Jiwen Lu , Jie Zhou IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2020 [Paper] We propose a graph interaction networks (GINs) model for transferring relation knowledge across two graphs two different scenarios for video analysis, including a new proposed setting for unsupervised skeleton-based action recognition across different datasets, and supervised group activity recognition with multi-modal inputs. |
|
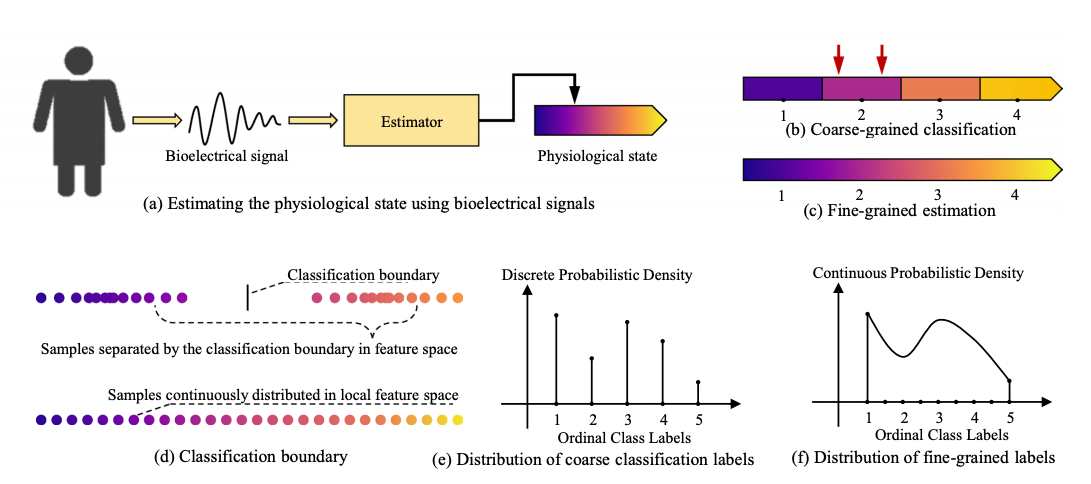
Zengyi Qin , Jiansheng Chen , Zhenyu Jiang , Xumin Yu, Chunhua Hu, Yu Ma, Suhua Miao and Rongsong Zhou Scientific Reports , 2020 [Paper] [Code] Our method allows machine learning algorithms to perform fine-grained estimation of physiological states (e.g., sleep depth) even if the training labels are coarse-grained. |
|
|
|
|