|
I am currently a senior researcher at Tencent Hunyuan, working on large multimodal models and physical AI foundation models. I obtained my Ph.D. degree from the Intelligent Vision Group (IVG), Department of Automation, Tsinghua University in 2025, advised by Prof. Jiwen Lu and Jie Zhou. Before that, I received my B.Eng. degree from the Department of Electronic Engineering, Tsinghua University in 2020. I am broadly interested in large language model and computer vision. My current research focuses on multi-modal large language models and large vision models. |

|
|
|
|
* indicates equal contribution |
|
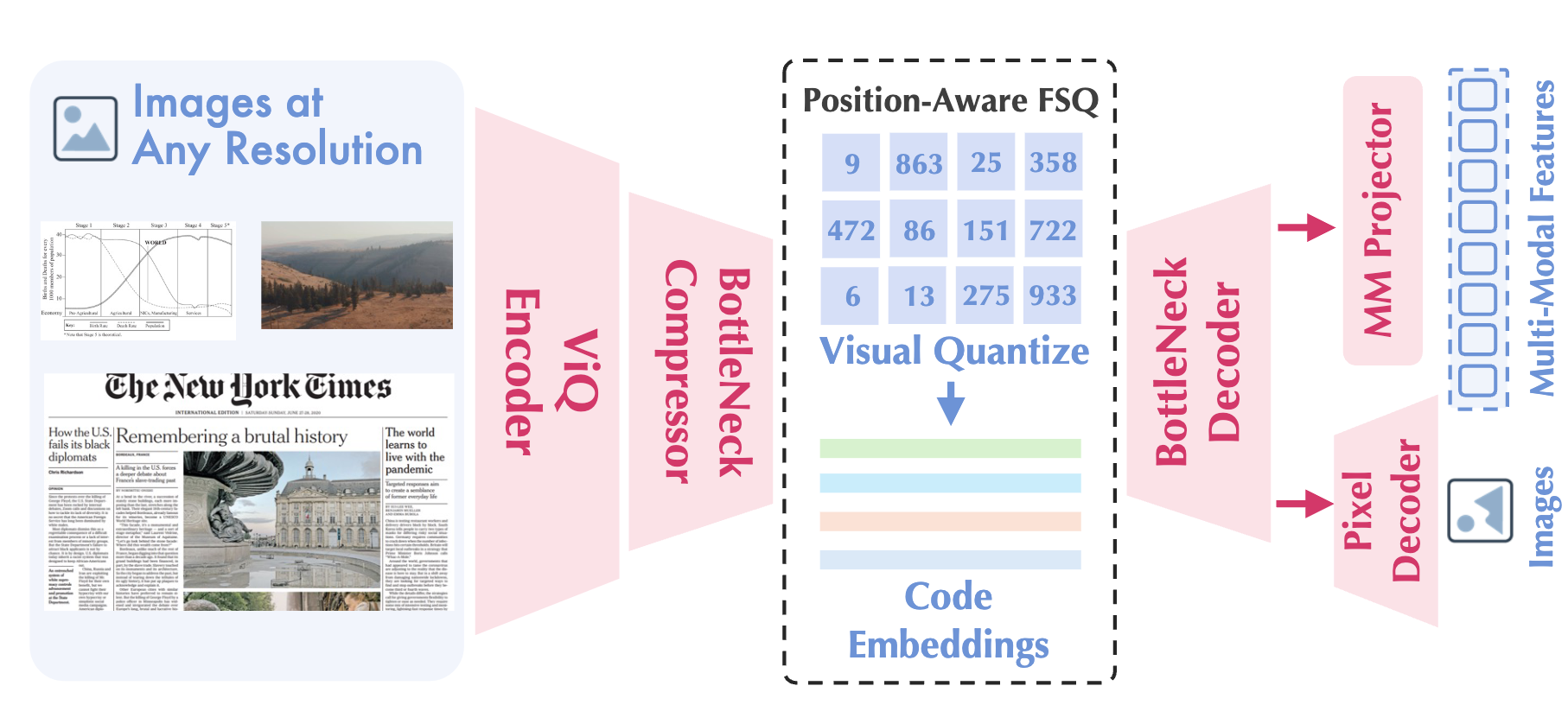
Xumin Yu*, Zuyan Liu*, Zhenyu Yang*, Yuhao Dong, Shengsheng Qian, Jiwen Lu, Han Hu, Yongming Rao# European Conference on Computer Vision (ECCV), 2026 [arXiv] [Code] [Models] ViQ is a framework for discrete visual representations that balances semantics and details while supporting native-resolution inputs, serving as a unified, general discrete representation for arbitrary visual inputs for both understanding and high-fidelity reconstruction. |
|
Xumin Yu*, Zuyan Liu*, Ziyi Wang*, He Zhang*, Yongming Rao#, Fangfu Liu, Yani Zhang, Ruowen Zhao, Oran Wang, Yves Liang, Haitao Lin, Minghui Wang, Yubo Dong, Kevin Cheng, Bolin Ni, Rui Huang, Han Hu, Zhengyou Zhang, Linus, Shunyu Yao Technical Report, 2026 [arXiv] [Code] [Models] HY-Embodied-0.5 is the first version of our embodied foundation models for real-world agents, attaining best performance on 16 out of 22 widely used benchmarks of visual perception, spatial intelligence and embodied reasoning. |
|
|
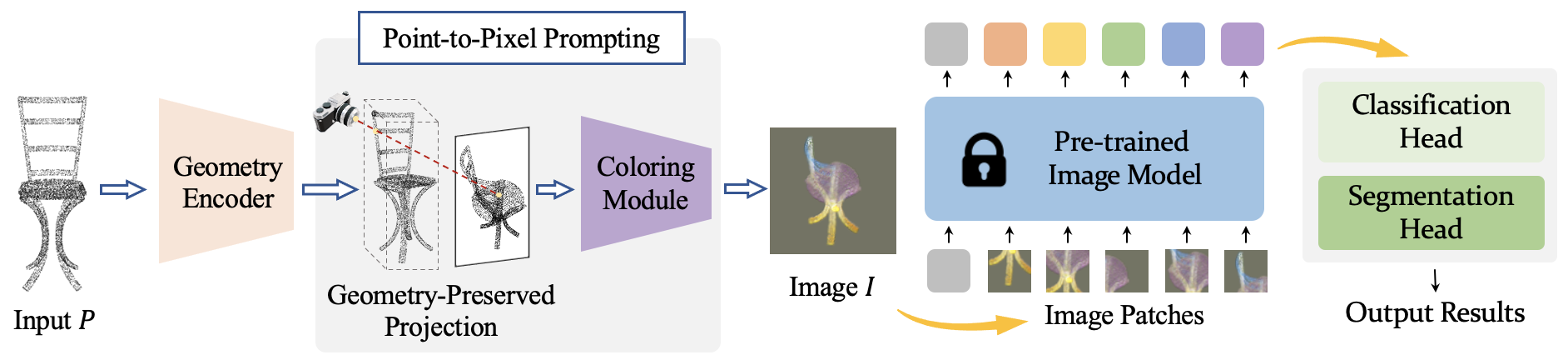
Ziyi Wang*, Xumin Yu*, Yongming Rao*, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 Spotlight [arXiv] [Code] [Project Page] [中文解读] P2P is a framework to leverage large-scale pre-trained image models for 3D point cloud analysis. |
|
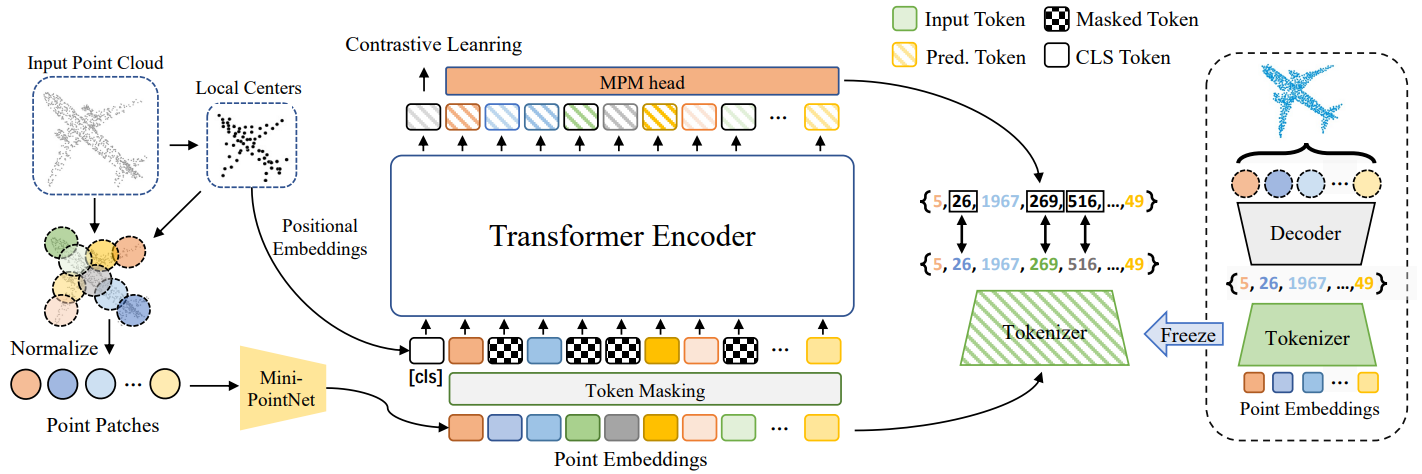
Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] Point-BERT is a new paradigm for learning Transformers in an unsupervised manner by generalizing the concept of BERT onto 3D point cloud data. |

|
Xumin Yu*, Yongming Rao *, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [supp] [Code] [中文解读 (by CVer)] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
|
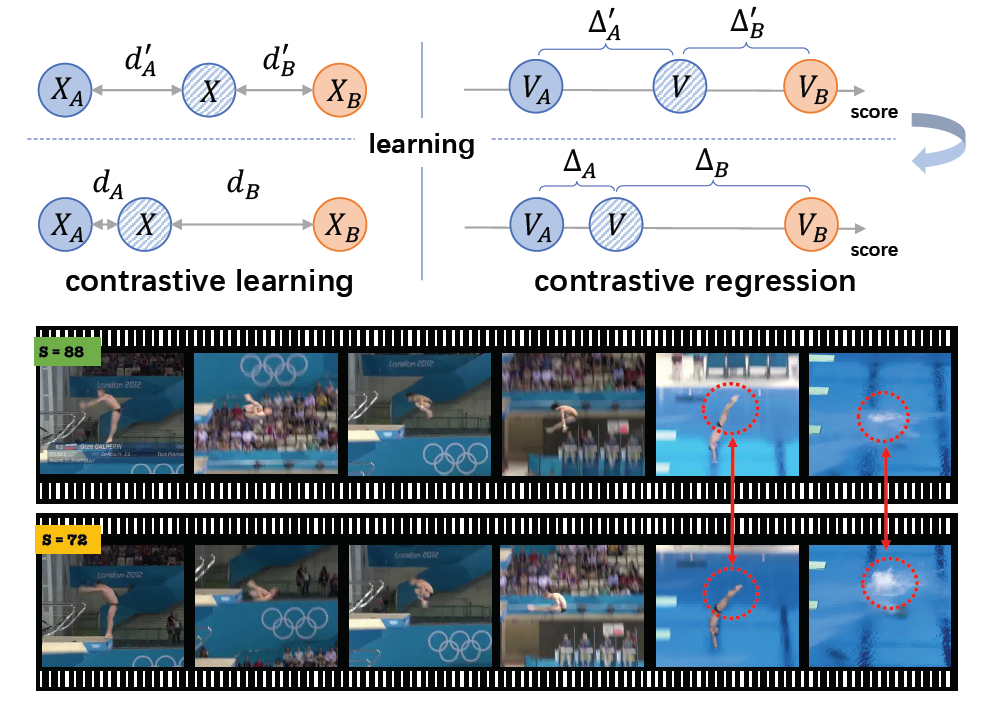
Xumin Yu*, Yongming Rao*, Wenliang Zhao, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We propose a new contrastive regression (CoRe) framework to learn the relative scores by pair-wise comparison, which highlights the differences between videos and guides the models to learn the key hints for assessment. |
|
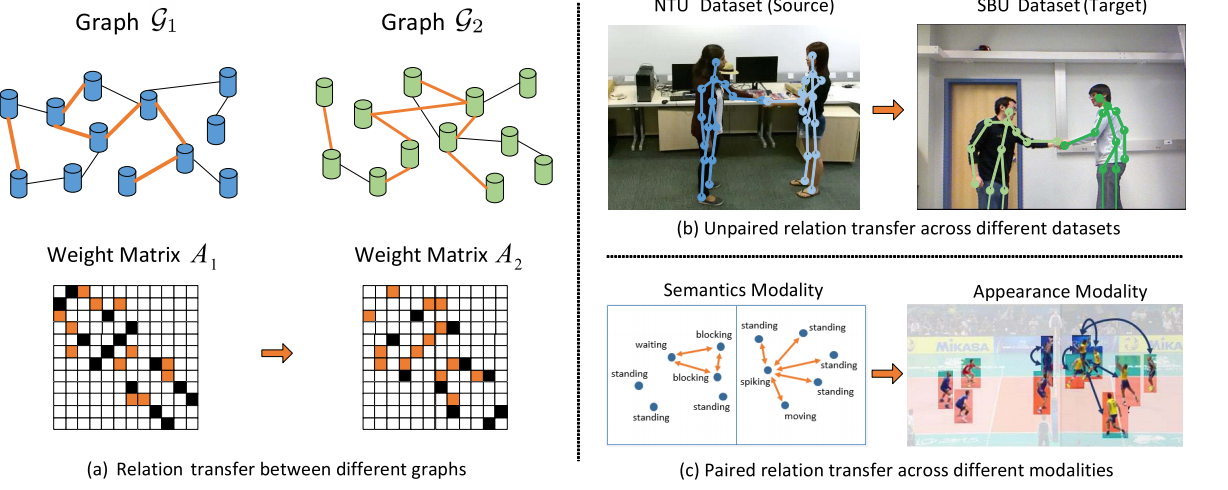
Yansong Tang, Yi Wei , Xumin Yu, Jiwen Lu , Jie Zhou IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2020 [Paper] We propose a graph interaction networks (GINs) model for transferring relation knowledge across two graphs two different scenarios for video analysis, including a new proposed setting for unsupervised skeleton-based action recognition across different datasets, and supervised group activity recognition with multi-modal inputs. |
|
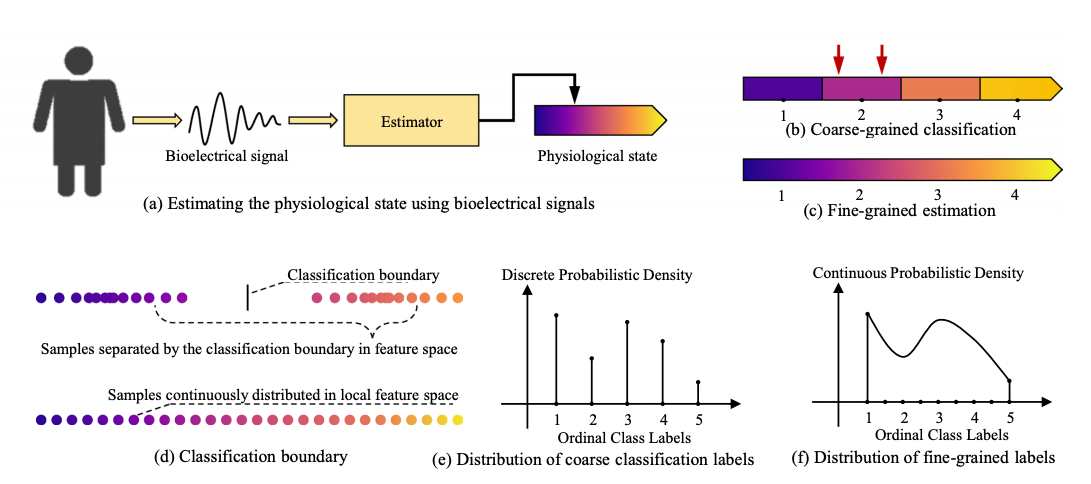
Zengyi Qin , Jiansheng Chen , Zhenyu Jiang , Xumin Yu, Chunhua Hu, Yu Ma, Suhua Miao and Rongsong Zhou Scientific Reports , 2020 [Paper] [Code] Our method allows machine learning algorithms to perform fine-grained estimation of physiological states (e.g., sleep depth) even if the training labels are coarse-grained. |
|
|

|
Multi-Modal Model Group, Researcher Topic: Multi-Modal |

|
Intelligent Creation Group, Research Intern Topic: Human AIGC |
|
|
|
|